Web Speech API语音识别和合成
前言
Web Speech API 提供了两类不同方向的函数——语音识别和语音合成 (也被称为文本转为语音,英语简写是 tts)。传统的语音识别和合成一般使用各个厂商提供的开放API,或者有实力的企业可以自己研发对应的API使用,而有了Web Speech之后我们可以直接在Web App中原生使用语音识别技术,尽管目前这项技术还不太成熟,这篇文章将为大家简单的介绍一下这个API。
Web Speech有两类API:
1、语音识别(Speech Recognition)-----------> 语音转文字
2、语音合成(Speech Synthesis) -----------> 文字变语音
一、Speech Recognition(语音识别)
Speech recognition(语音识别) 涉及三个过程:首先,需要设备的麦克风接收这段语音;其次,speech recognition service(语音识别服务器) 会根据一系列语法 (基本上,语法是你希望在具体的应用中能够识别出来的词汇) 来检查这段语音;最后,当一个单词或者短语被成功识别后,结果会以文本字符串的形式返回 (结果可以有多个),以及更多的行为可以设置被触发。
Web Speech API 有一个主要的控制接口——SpeechRecognition, 外加一些如表示语法、表示结果等等亲密相关的接口。通常,设备都有可使用的默认语音识别系统,大部分现代操作系统使用这个语音识别系统来处理语音命令,比如 Mac OS X 上的 Dictation,iOS 上的 Siri,Win10 上的 Cortana,Android Speech 等等。
1、浏览器支持
对于 Web Speech API speech recognition(语音识别) 的支持,在各浏览器中还不成熟,主要浏览器兼容性如下
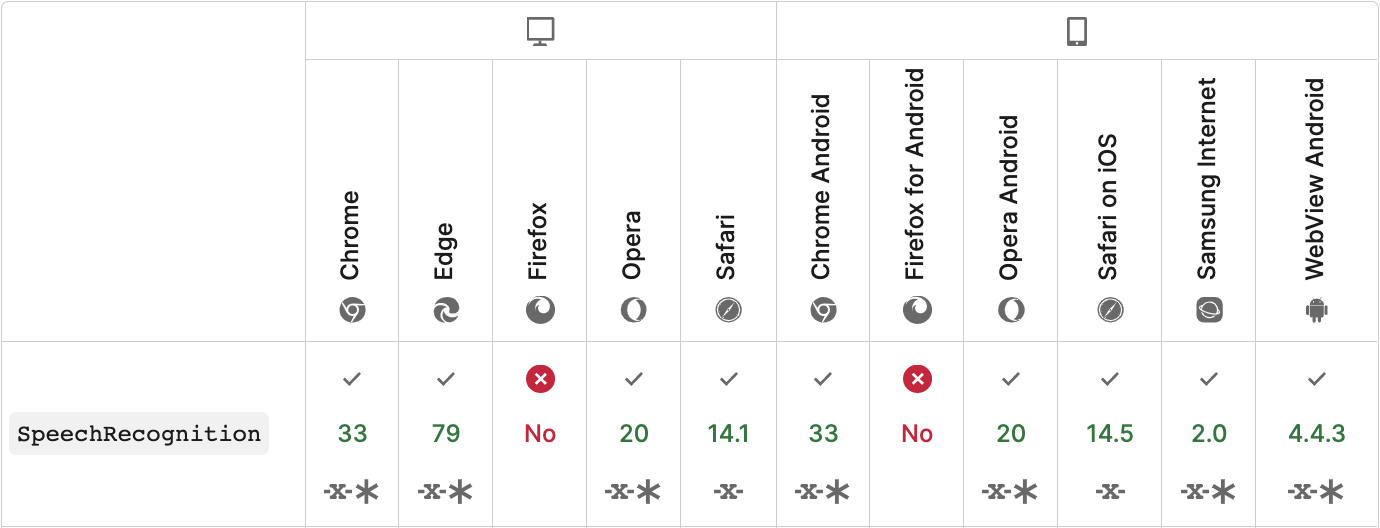
Chrome 现在支持的是带有前缀的 speech recognition,因此在 code 开始部分得加些内容保证在需要前缀的 Chrome 和不需要前缀的像 Firefox 中,使用的 object 都是正确的
const SpeechRecognition = window.webkitSpeechRecognition || window.SpeechRecognition
if (SpeechRecognition){
const speechrecognition = new SpeechRecognition()
}注意,在浏览器中调用此功能语音识别是不准确的。Chrome 的处理方式时获取音频并将其发送到 Google 的服务器以转换为文本,目前在不翻墙的情况下使用该API会报网络问题的错误。而在safair浏览器中使用该API的时候会获取设备本身的语音识别权限进行转换文本,无需翻墙
2、属性和方法
a)、属性
continous:是否让浏览器始终进行语言识别,默认为false,也就是说,当用户停止说话时,语音识别就停止了。这种模式适合处理短输入的字段。
maxAlternatives:设置返回的最大语音匹配结果数量,默认为1
lang:设置语言类型,默认值就继承自HTML文档的根节点或者是祖先节点的语言设置。
b)、方法
start():启动语音识别
stop():停止语音识别
abort():中止语音识别
3、事件
开始识别语音时浏览器会询问用户是否许可浏览器获取麦克风数据
这个API提供了11个事件。
audiostart:当开始获取音频时触发,也就是用户允许时。
audioend:当获取音频结束时触发
error:当发生错误时触发
nomatch:当找不到与语音匹配的值时触发
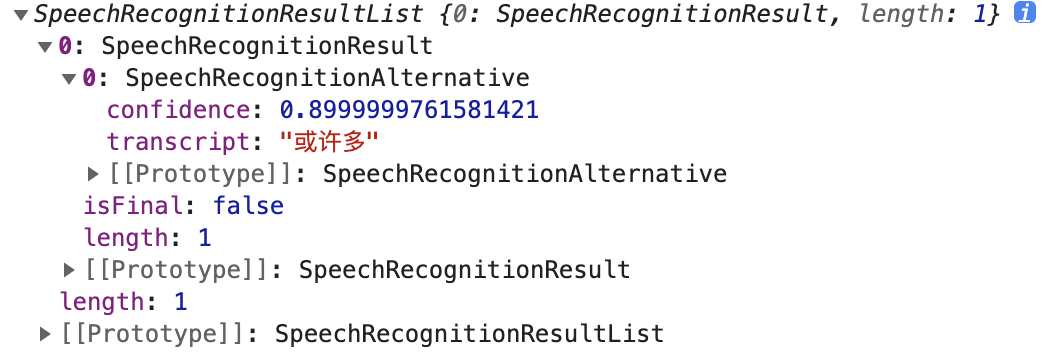
result: 当得到与语音匹配的值时触发,它传入的是一个SpeechRecognitionEvent对象,它的results属性就是语音匹配的结果数组,最匹配的结果排在第一位。该数组的每一个成员是SpeechRecognitionResult对象,该对象的transcript属性就是实际匹配的文本,confidence属性是可信度(在0到1之间)
soundstart
soundend
speechstart
speechend
start:当开始识别语言时触发
end:当语音识别断开时触发
4、实例
<Button onClick={handleToggleSpeech}>{recordStatus === 0 ? 'Start' : 'Stop'}</Button>
const initRecognition = () => {
const SpeechRecognition = window.webkitSpeechRecognition || window.SpeechRecognition
if (SpeechRecognition){
const speechrecognition = new SpeechRecognition()
// speechrecognition.lang = 'cmn-Hans-CN'
speechrecognition.continuous = true;
speechrecognition.interimResults = true;
setRecognition(speechrecognition)
speechrecognition.onresult = handleResult
speechrecognition.onerror = (e) => {
console.error('错误,请重试', e);
}
speechrecognition.onend = (e) => {
console.log('录音结束', e);
stop()
}
}
}
const handleResult = (event) => {
if(event.results.length > 0) {
const arr = []
for (const res of event.results) { ①
arr.push(res[0].transcript)
}
setSpeechValue(arr.join(';'))
}
}
const handleToggleSpeech = () => {
recordStatus === 0 ? start() : stop()
}
const start = () => {
recognition.start();
setRecordStatus(1)
};
const stop = () => {
setRecordStatus(0)
recognition && recognition.stop();
}①:SpeechRecognitionEvent.results属性返回的是一个SpeechRecognitionResultList对象 (这个对象会包含SpeechRecognitionResult 对象们),它有一个 getter,所以它包含的这些对象可以像一个数组被访问到。每个SpeechRecognitionResult 对象包含的 SpeechRecognitionAlternative 对象含有一个被识别的单词。这些SpeechRecognitionResult 对象也有一个 getter,所以[0] 返回的是其中包含的第一个SpeechRecognitionAlternative对象。最后返回的transcript属性就是被识别单词的字符串。
二、Speech synthesis(语音合成)
语音合成 (也被称作是文本转为语音,英语简写是 tts) 包括接收 app 中需要语音合成的文本,再在设备麦克风播放出来这两个过程。
Web Speech API 对此有一个主要控制接口——SpeechSynthesis,外加一些处理如何表示要被合成的文本 (也被称为 utterances),用什么声音来播出 utterances 等工作的相关接口,这一步使用SpeechSynthesisUtterance来对文本处理。同样的,许多操作系统都有自己的某种语音合成系统,在这个任务中我们调用可用的 API 来使用语音合成系统。
1、浏览器支持
Web Speech API 语音合成部分在各浏览器中还是在发展,还不成熟,浏览器兼容性如下图:
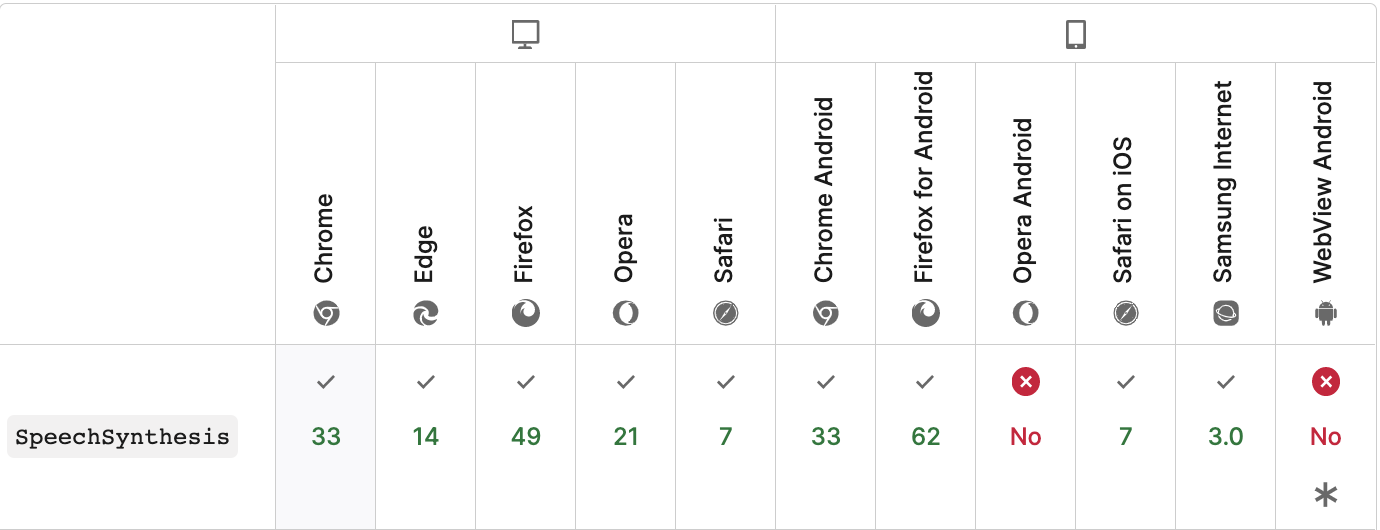
SpeechSynthesis API在Chrome和Firefox中都不需要前缀
2、属性和方法
1)、SpeechSynthesisUtterance对象
SpeechSynthesisUtterance对象的构造可以直接传递要读的内容,这里我们也可以通过给实例对象的属性赋值来设置要读的内容,使用方式如下
const utterance: SpeechSynthesisUtterance = new SpeechSynthesisUtterance(speakValue); utterance.voice = currentVoice as SpeechSynthesisVoice; utterance.lang = "zh-CN"; // 使用的语言:中文 utterance.volume = 10; // 声音音量:1 utterance.rate = 1; // 语速:1 utterance.pitch = 1;
a)、属性
text:要合成的文字内容,字符串
volume:声音的音量,区间范围是0到1,默认是1
rate:语速,数值,默认值是1,范围是0.1到10,表示语速的倍数,例如2表示正常语速的两倍
pitch:表示说话的音高,数值,范围从0(最小)到2(最大)。默认值为1
voice:说出话语的声音
lang:使用的语言,字符串, 例如:“zh-CN”
b)、方法
onstart:语音开始合成时触发
onpause:语音暂停时触发
onresume:语音合成重新开始时触发
onend:语音结束时触发
2)、speechSynthesis对象
创建完SpeechSynthesisUtterance对象之后,把这个对象传递给speechSynthesis对象的speak方法中。该对象主要是控制合成行为的,实现如下:
speechSynthesis.speak(utterance);
a)、方法
speak:只能接收SpeechSynthesisUtterance作为唯一的参数,作用是读合成的话语
stop:立即终止合成过程
pause:暂停合成过程
cancel:接口从话语队列中删除所有的话语
resume:重新开始合成过程
getVoices: 此方法用来返回浏览器支持的语音包列表数组,SpeechSynthesisUtterance对象中使用的voice就是从这个API获取到的数组中设置的,该数据较大程度取决于操作系统
3、实例
<Input.TextArea
onChange={handleChange}
style={{ width: '50vw', marginBottom: 16 }}
rows={5}
/>
<div style={{ display: 'flex' }}>
<Select value={currentVoice?.voiceURI} showSearch onChange={handleChangeVoice} style={{ width: 200, marginRight: 16 }}>
{voicesList.map(d => {
return <Select.Option key={d.voiceURI} value={d.voiceURI}>{d.name}</Select.Option>
})}
</Select>
<Button onClick={handleSpeak}>Speak</Button>
</div>
const [speakValue, setSpeakValue] = useState('')
const [currentVoice, setCurrentVoice] = useState<SpeechSynthesisVoice>();
const [voicesList, setVoicesList] = useState<Array<SpeechSynthesisVoice>>([])
const getVoice = () => {
const synth = window.speechSynthesis;
const voices: Array<SpeechSynthesisVoice> = synth.getVoices();
const defaultVoice = voices.find(d => d.default)
setVoicesList(voices);
setCurrentVoice(defaultVoice)
}
const handleChange = (e: BaseSyntheticEvent) => {
setSpeakValue(e.target.value)
}
const handleSpeak = () => {
if (!speakValue) return;
const utterance: SpeechSynthesisUtterance = new SpeechSynthesisUtterance(speakValue);
utterance.voice = currentVoice as SpeechSynthesisVoice;
utterance.lang = "zh-CN"; // 使用的语言:中文
utterance.volume = 10; // 声音音量:1
utterance.rate = 1; // 语速:1
utterance.pitch = 1;
speechSynthesis.speak(utterance);
}
const handleChangeVoice = (value: string) => {
const voice = voicesList.find(d => d.voiceURI === value)
setCurrentVoice(voice)
}三、结语
本文内容主要为大家介绍了Web Speech API一些主要API接口的属性和方法以及相关概念,此功能某些浏览器尚在开发中,由于该功能对应的标准文档可能被重新修订,所以在未来版本的浏览器中该功能的语法和行为可能随之改变。所以该技术建议暂时不要在正式产品上使用,现阶段大家可以先去了解这个功能,待该功能稳定并有了统一的标准文档以及各个浏览器兼容性较高的情况下再酌情使用,目前如果需要使用到语音合成或者识别功能可以使用各大厂商的开放API,亦或者可以去从底层解析语音,自己开发可使用的API。
